
La dernière fois que je suis allé au Fosdem c’était en 2014. Mais j’avais bien l’intention d’y retourner, et c’est enfin chose faite. Alors, quoi de beau dans cette version 2017 ?
Beaucoup de conférences
… et BEAUCOUP de monde 25 salles, donc 25 conférences en parallèles sur deux jours. Autant dire qu’il y en avait pour tous les goûts (stockage, bdd, développement kernel, scripts, web, open hardware, sécurité, philosophie du libre etc, etc). Dans le détail, vous trouverez ici le planning détaillé du samedi et du dimanche sur le site (un clic sur le nom de la conf permet d’avoir une description plus précise de son contenu). Pourquoi je vous parle de ça alors que c’est passé ? Parce que progressivement les vidéos des conférences sont mises en ligne.
Elles sont organisées par salle, d’où l’intérêt des 2 agenda présentés juste au dessus et j’espère bien pouvoir, grâce aux vidéos, assister à toutes les conférences que j’ai raté parce que les salles étaient pleines.
Les conf auxquelles je voulais le plus assister
- Relax and recover : Un logiciel de « disaster recovery » basé sur un ensemble de script. A tester…
- Playing with the light : Ayant acheté des philips Hue, je voulais vraiment assister à celle la mais… Salle pleine !
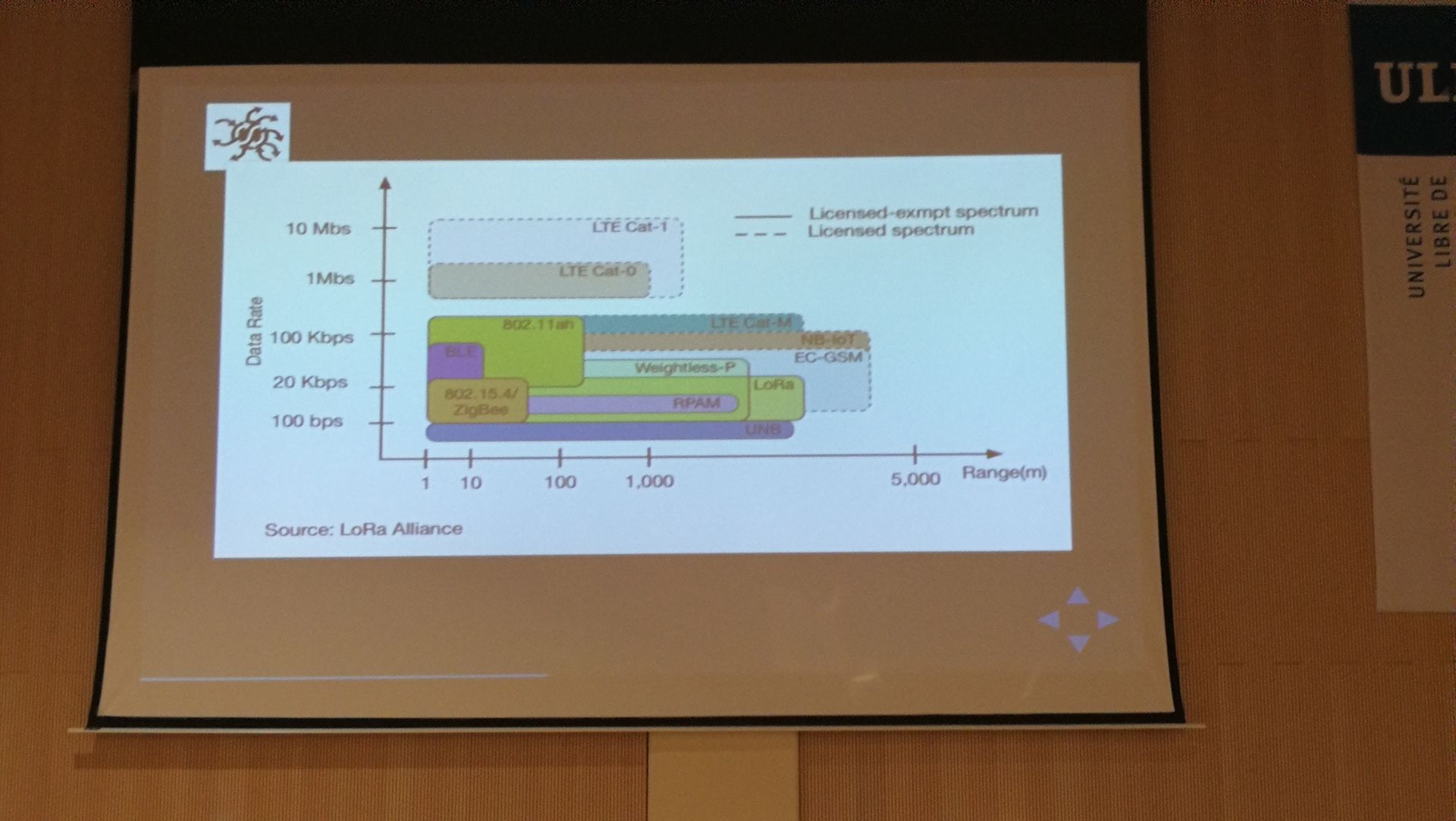
- LoraWan ofr exploring I.O.T : J’ai appris des choses sur cette « internet of thing » et les protocoles sous jacent (voir capture plus haut)
- LizardFS : FS distribué.. Mais non, la j’avais trop faim. * Pretty easy privacy : Salle pleine…
- Privacy in Practice for self hosting : Rien a voir avec ce que j’imaginai… Assez inintéressant au final.
It’s time to SAFE the Internet

L’une des plus sympathique à laquelle j’ai assisté s’intitulait « it’s time to safe the Internet » (disponible ici). Et pour une fois, comme ça se passait dans l’un des plus grand amphi, il y avait de la place. Je croyais au départ qu’il s’agissait juste d’un nouvel outil d’anonymisation type tor au freenet, (et je n’avais pas totalement tord, un tel logiciel est effectivement en cours de développement) Mais la vision du conférencier était beaucoup plus large que cela. Il a commencé par nous faire réaliser que ce ne sont pas seulement les données qui sont centralisées aujourd’hui (avec tous les problèmes que cela posent au niveau surveillance etc), le problème est bien plus profond, au cœur même des protocoles utilisées aujourd’hui. En effet, une url ne décrit rien d’autre qu’une localisation. (ip d’un serveur, répertoire et fichier). Nous raisonnons donc toujours, sans même nous en rendre compte, uniquement en terme de localisation de l’information. Bien sur, des exceptions existent (liens magnets…). Mais les protocoles P2P actuels ne sont pas utilisables tel quel pour remplacer le web. Il manque en effet des briques fondamentales. Par exemple le fait de pouvoir versionner un document, ce qui passe par l’identification d’un « référent » (auteur du document ou autre). Bref, il faut gérer les mises à jour, mais il faut aussi pouvoir publier un document en étant certain, au contraire, que personne ne pourra jamais remonter jusqu’à son auteur (comme dans Freenet). En résumé, Benjamin Kampmann à retourner le problème dans tous les sens et il pense avoir trouvé une solution technique qui permette de faire tout cela. Il est parti du protocole Kademlia (explications techniques sur le fonctionnement de kadmelia ici) puis il a ajouté (et ajoute toujours) les briques qui manquent pour remplacer totalement les protocoles que nous connaissons (http etc).
Je n’ai pas forcément tout suivi mais c’était vraiment intéressant. Il à pris l’exemple d’un site web basique avec un forum. Le site et le moteur du forum serait crée par le propriétaire du site. Mais chaque interventions sur le forum n’appartiendrait qu’a son auteur. Personne d’autre que l’auteur du commentaire ne pourrait le modifier ou le supprimer. (Fonctionnement par un mécanisme de clef publique/privée). A l’inverse, il serait toujours possible de publier du contenu qui n’appartiendrait à personne en utilisant des clefs basés sur une CA auto-signé à l’inverse des CA « personnels ». Bon, je ne rentre pas plus dans le détail parce que j’aurai trop peur de raconter des bêtises… Le plus simple, c’est que vous regardiez vous même la vidéo. Et globalement, comme on à pas tous les mêmes centres d’intérêts, n’hésitez pas à fouiller dans le planning pour trouver les sujets qui vous intéresse et jetez un œil aux vidéos correspondantes. C’est moins sympa que d’être physiquement sur place, mais on apprend des choses quand même… (A condition de ne pas avoir de soucis avec l’anglais).
